

TL;DR
Discover how Mitzu overcomes the limitations of SQL-based product analytics in data warehouses, providing insights without relying solely on data analysts. In my previous company, I worked as a team lead of data analysts and engineers.
Why Mitzu.io is the Future of Product Analytics?
In my previous company, I worked as a team lead of data analysts and engineers. It was a medium size SaaS product development company.
Basically, product managers, marketers, salespeople (etc) came to us with requests, and we tried to deliver them ASAP. We collected the usage data from the web application into our data warehouse with Segment.
We avoided Google Analytics, Mixpanel and similar for security and privacy reasons. Also, transferring the data to external tools would have increased our operating costs significantly.
All this meant data analysts answered all product-related questions in the data warehouse.

The Challenge of Cohort User Retention
One of the main metrics the company wanted to track was cohort user retention. With that, we wanted to see what impact the application changes had on newly acquired users.
Measuring cohort retention using SQL seemed simple enough as we already had all user behavioural data in our data warehouse. However, a devil sitting on my shoulder nudged me to do a little experiment.
Unexpected Results from Data Analysts
“What is the week-over-week retention of our users that visited our website on the week of 2023–01–02?”
Who Was Right?
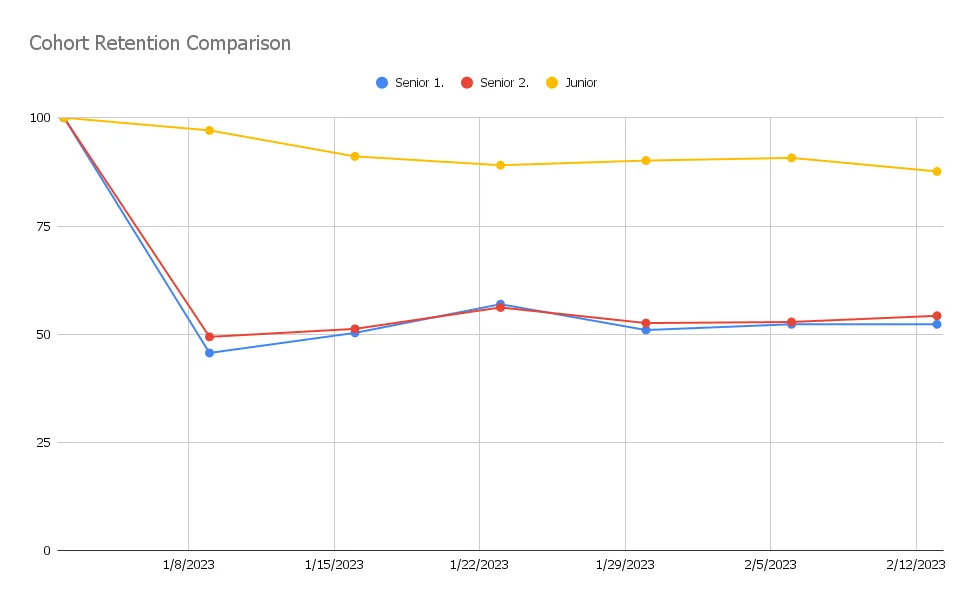
To my surprise, all three data analysts came back with different results. Down below you can see the differences (for the cohort 2023–01–02).
The charts describe the percentage of users visiting the application week over week after the initial week of 2023–01–02.
Analyzing SQL Approaches
Here are the 3 SQL snippets. I simplified them a bit so they are easier to read.
Junior Analyst’s Code
WITH weekly_users AS (
SELECT
date_trunc('WEEK', pe.event_time) AS week,
count(distinct pe.user_id) user_count
FROM page_visits pe
GROUP BY 1
),
first_week AS (
SELECT user_count,
week
FROM weekly_users
WHERE week = DATE('2023-01-02')
)
SELECT
fw.week AS cohort_week,
wu.week AS retention_week,
fw.user_count*100.0 / wu.user_count
FROM weekly_users wu
JOIN first_week fw ON wu.week >= fw.weekThis one has an obvious flaw. In the JOIN the user IDs are ignored. The final SELECT doesn’t care if the same users are retained as in the initial week.
First Senior Analyst’s Code
WITH events AS (
SELECT DISTINCT
user_id,
date_trunc('WEEK', event_time) AS week
FROM page_visits
)
SELECT
c.week cohort_week,
(count(DISTINCT w1.user_id) * 100.0) / count(DISTINCT c.user_id) AS week_1,
(count(DISTINCT w2.user_id) * 100.0) / count(DISTINCT c.user_id) AS week_2,
(count(DISTINCT w3.user_id) * 100.0) / count(DISTINCT c.user_id) AS week_3,
(count(DISTINCT w4.user_id) * 100.0) / count(DISTINCT c.user_id) AS week_4,
(count(DISTINCT w5.user_id) * 100.0) / count(DISTINCT c.user_id) AS week_5,
(count(DISTINCT w6.user_id) * 100.0) / count(DISTINCT c.user_id) AS week_6
FROM events c
LEFT JOIN events w1 ON c.user_id = w1.user_id AND w1.week = c.week + interval '7' day
LEFT JOIN events w2 ON c.user_id = w2.user_id AND w2.week = c.week + interval '14' day
LEFT JOIN events w3 ON c.user_id = w3.user_id AND w3.week = c.week + interval '21' day
LEFT JOIN events w4 ON c.user_id = w4.user_id AND w4.week = c.week + interval '28' day
LEFT JOIN events w5 ON c.user_id = w5.user_id AND w5.week = c.week + interval '35' day
LEFT JOIN events w6 ON c.user_id = w6.user_id AND w6.week = c.week + interval '42' day
WHERE c.week = DATE('2023-01-02')
GROUP BY 1This one was cool as it was very easy to read. However, my main problem with it is that it can be difficult to extend and iterate on. Also not very suitable for analytics tools for the same reason.
Second Senior Analyst's Code
WITH cohort AS (
SELECT
user_id,
DATE_TRUNC('week', MIN(event_time)) AS cohort_week
FROM
page_visits
GROUP BY
1
),
retention AS (
SELECT
cohort.cohort_week,
DATE_TRUNC('week', event_time) AS event_week,
COUNT(DISTINCT page_visits.user_id) AS weekly_active_users
FROM
cohort
JOIN page_visits ON cohort.user_id = page_visits.user_id
GROUP BY
1,
2
)
SELECT
retention.cohort_week,
retention.event_week,
round(retention.weekly_active_users *100.0 / cohort_size,2) AS retention_rate
FROM
retention
JOIN (
SELECT
cohort_week,
COUNT(DISTINCT user_id) AS cohort_size
FROM
cohort
GROUP BY
1
) AS cohort_size ON retention.cohort_week = cohort_size.cohort_week
WHERE retention.cohort_week = DATE('2023-01-02')
ORDER BY
1,
2;I liked this one much more, as it was robust and easy to extend. For example, switching from week-over-week to month-over-month would require only 2 changes and a couple of renamings.
Limitations of Manual SQL Analysis
We kept the second senior analyst’s solution. However, it got me thinking:
Time-Consuming Process
It took (on average) 1 hour to write the queries.Is this the most efficient way to get these results
Inconsistent Outcomes
The second analyst’s results were very close to the first’s.Who was correct?(hint: neither of them, which I will cover in a future blog post 😃)
Scalability Issues
We get similar many product usage-related questions about user funnels and segmentation every day.Can’t these tasks be automated?
Introducing Mitzu: Warehouse-native Product Analytics
With this short story, I wanted to highlight 3 problems with product analytics in the data warehouse:
- It can be tediously slow. Product managers, sales, and marketing people in an organisation have hundreds of similar questions daily. Data analysts have more critical tasks than answering these questions.
- With people from different backgrounds and experiences, the results will be just as different for each product analytics question. The answers depend on who you ask.
- I believe non-techy people should be able to gain insights from company data without a middleman or copying data to external tools like GA or Mixpanel.
These problems motivated me to start working on my first startup project mitzu.io.
Key Features of Mitzu:
- No-code
- Self-served
- Product analytics web-application
- Supports: Snowflake, Databricks, Redshift, Athena, Postgres, MySQL, Trino, etc.
- Handles retention, user funnel and event segmentation type of questions (and more)
Streamlined Cohort Retention Analysis
Putting together a cohort user retention metric takes less than a minute.
Mitzu generates a SQL that was reviewed by multiple data analysts and data scientists.
WITH anon_1 AS
(SELECT DISTINCT ecommerce.page_events.user_id AS _cte_user_id,
date_trunc('MINUTE', ecommerce.page_events.event_time) AS _cte_datetime,
NULL AS _cte_group
FROM ecommerce.page_events
WHERE ecommerce.page_events.event_name = 'page_visit'
AND ecommerce.page_events.event_time >= timestamp '2021-10-01 00:00:00'
AND ecommerce.page_events.event_time = timestamp '2021-10-01 00:00:00'
AND ecommerce.checkout_events.event_time date_add('week', ret_indeces._ret_index, anon_1._cte_datetime)
AND anon_2._cte_datetimeIt is hard to read, but that is not the goal here.
The Advantages of Mitzu Over Traditional SQL Methods
Product analytics with SQL over the data warehouse:
- can be very slow
- produces inconsistent results
- scales poorly since data analysts are a bottleneck
Mitzu is a tool that can help any product development company analyze usage behavioural data natively from the data warehouse.


