TL;DR
Discover how to use the connected components algorithm to unify user aliases in a single table, enabling seamless tracking and analysis across all datasets. User identification in data is a recurring problem for warehouse-first B2C companies.
Why User Identification is Complex in B2C Companies?
User identification in data is a recurring problem for warehouse-first B2C companies. A single user can be identified with multiple aliases in the datasets:
✅ user_id - ID after sign-in✅ device_id - Mobile or desktop device's ID✅ anonymous_id - Tracking cookie✅ customer_id - Stripe✅ contact_id - Hubspot✅ email - Used for sign-in... and many more.
The Risks of Using a Single Identifier for Users
Picking a single identifier for user identification is risky. You may end up:❌ not being able to use that identifier for all your users❌ multiple identifiers for the same user
Retroactive User Recognition: Merging IDs for Accurate Tracking
ℹ️ The correct solution is to merge all these IDs into a single merged ID and create a user alias table where all aliases are associated with their merged IDs.
This approach is called retroactive user recognition and it simplifies data modelling significantly. You won't have to think about which ID to use in joins. You can safely use the merged ID once they are backfilled to the all tables.
Example: How to Handle Multiple User Aliases in Clickstream Data
It is the simplest to explain this challenge with an example. Imagine you have a dataset that contains page visits of users.
It has four columns:
- event_time
- anonymous_id
- url
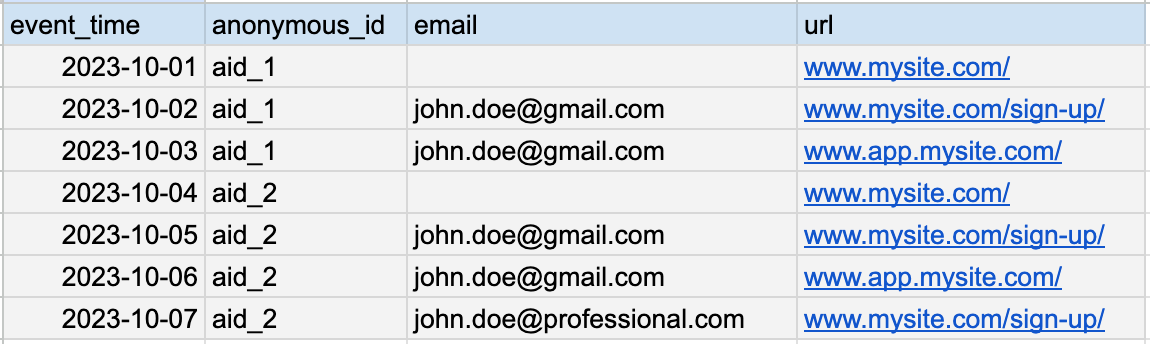
The anonymous_id is always filled from the browser's cookie. However, it changes if the browser cookie is refreshed. The email is filled once the user logs into the application. However, it changes if the user logs in with another email.
Now, you need to answer a simple question:
Creating a User Alias Table: Simplifying Data Modeling with Merged IDs
As you can see, no single column can uniquely identify the user. In fact, all of its anonymous_ids and emails identify the users. The anonymous_id and the emails are only aliases for the same user. What you need is a user_alias table that contains all aliases.
The alias table is the association of all the users' aliases to a single merged_id that can be used to track that user across all datasets.
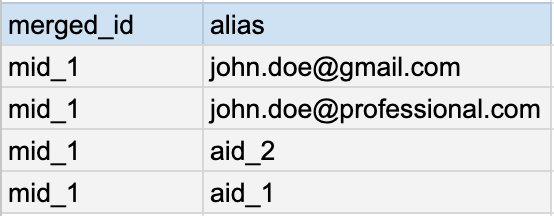
Creating and backfilling all aliases where it is missing is the process of retroactive user recognition.
Why Building a User Alias Table is More Than Just SQL Joins?
Creating the user aliases table is way more complex than you think. Most people approach it with some special joins and group bys. However, building that alias table is impossible with only simple joins and group bys with SQL.
Why? Because the problem of user aliases is, in fact, a graph problem.
User with anonymous_id aid_1 signs in with email (john.doe@gmail.com). The browser clears the cookie at some point, so the user is also signed out. The user signs in again while having the new cookie. At another point, the user switches to the company email (john.doe@professional.com), which is typical for SaaS businesses.
We are still talking about the same user who has four aliases.
Here is the change graph of alias associations for our user:
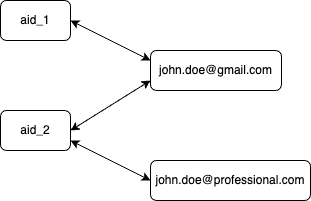
As you can see, none of the anonymous_ids or emails are an excellent identifier for the user. We need to define a new ID uniquely associated with the user. The best way to do this is to have the whole graph as the source of the unique ID.
Once we have a unique ID, we can backfill it to all events in the table and be able to support the two original requirements.
Walking the Graph: Using Recursive CTEs to Map User Aliases
To map out all the aliases, we must walk through all edges in this graph. Graph walking in SQL is only possible to do with recursive CTEs. In this example we are using Postgres SQL, with minor changes this SQL can ported to all SQL dialects.
First, we need to define the edges:
create table default.user_aliases as
WITH RECURSIVE
-- collecting the graph edges
edges as (
select
anonymous_id as a,
coalesce(email, anonymous_id) as b -- making sure users without sign up are also included
from page_visits
),
-- making sure the graph is bidirectional
bidirectional as (
select a,
b
from edges
union all
select b as a,
a as b
from edges
)create table default.user_aliases as
WITH RECURSIVE
-- collecting the graph edges
edges as (
select
anonymous_id as a,
coalesce(email, anonymous_id) as b -- making sure users without sign up are also included
from page_visits
),
-- making sure the graph is bidirectional
bidirectional as (
select a,
b
from edges
union all
select b as a,
a as b
from edges
)-- The connected components algorithm in SQL:
-- walking the graph to collect all aliases
walks AS (
SELECT
a as a,
a as b,
1 as depth
FROM bidirectional
UNION
SELECT w.a,
e.b,
depth + 1 as depth
FROM walks w
JOIN bidirectional e ON w.b = e.a
and not (
e.a = w.a
and e.b = w.b
)
and not (
e.b = w.a
and e.a = w.b
)
-- Termination condition
where depth < 10
)create table default.user_aliases as
WITH RECURSIVE
-- collecting the graph edges
edges as (
select
anonymous_id as a,
coalesce(email, anonymous_id) as b -- making sure users without sign up are also included
from page_visits
),
-- making sure the graph is bidirectional
bidirectional as (
select a,
b
from edges
union all
select b as a,
a as b
from edges
),
-- The connected components algorithm in SQL:
-- walking the graph to collect all aliases
walks AS (
SELECT
a as a,
a as b,
1 as depth
FROM bidirectional
UNION
SELECT w.a,
e.b,
depth + 1 as depth
FROM walks w
JOIN bidirectional e ON w.b = e.a
and not (
e.a = w.a
and e.b = w.b
)
and not (
e.b = w.a
and e.a = w.b
)
-- Termination condition
where depth < 10
)
-- picking the merged_id for all aliases
select
min(b) merged_id,
a as alias
from walks
group by 2create table default.user_aliases as
WITH RECURSIVE
edges as (
select
anonymous_id as a,
coalesce(email, anonymous_id) as b
from page_visits
union all
select
contat_id as a,
email as b
from hubspot_contacts -- extending with Hubspot
union all
select
customer_id as a,
email as b
from stripe_customers -- extending with Stripe
),
bidirectional as (
select a,
b
from edges
union all
select b as a,
a as b
from edges
),
walks AS (
SELECT
a as a,
a as b,
1 as depth
FROM bidirectional
UNION
SELECT w.a,
e.b,
depth + 1 as depth
FROM walks w
JOIN bidirectional e ON w.b = e.a
and not (
e.a = w.a
and e.b = w.b
)
and not (
e.b = w.a
and e.a = w.b
)
-- Termination condition
where depth < 10
)
select
min(b) merged_id,
a as alias
from walks
group by 2