TL;DR
Discover how Databricks products and Mitzu.io work together for real-time insights and accurate revenue attribution. Understanding user behavior is a critical component in the world of Software as a Service (SaaS), particularly in B2C contexts.
Understanding user behavior is a critical component in the world of Software as a Service (SaaS), particularly in B2C contexts. The ability to analyze and interpret billions of user events can spell the difference between a stagnant product and an ever-evolving, user-centric service.
The Challenge: Processing 8 Billion User Events in B2C SaaS
Recently, I had the opportunity to address a complex product analytics problem involving the management and processing of a staggering 8 billion user events over a two-year period, generated by a leading B2C SaaS CAD company’s application.
The primary problem was that access to relevant insights from this amount of data was sluggish at best. Answering some simple questions for product team often took hours or even days.
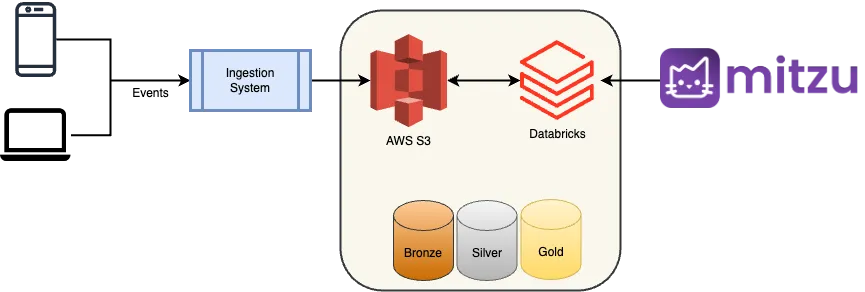
Streaming and Organizing Data: From JSON Files to S3 Data Lake
The data was streamed to an AWS S3 data lake in JSON-line files. Each file represented 15 minutes’ worth of application usage data and was methodically organized into distinct date partitions. This system allowed for daily iterative handling of the data.
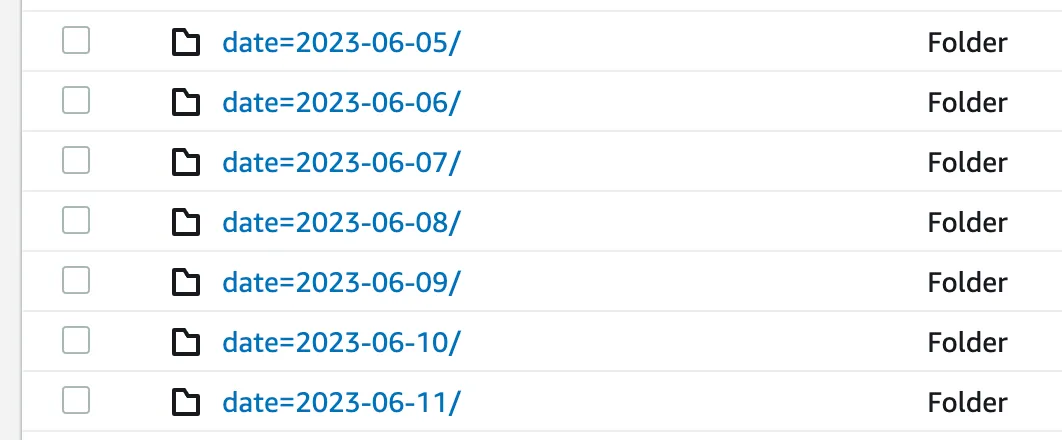
Example for events stored in JSON-line files:
{"event_type":"application_opened", "event_time":"2023-06-01T16:11:54.815479Z", "user_id":"4c17...", "event_properties":{"first_start": true}}
{"event_type":"button_clicked", "event_time":"2023-06-01T16:12:14.721323Z", "user_id":"2ec5...", "event_properties":{"button_name": "save"}}
{"event_type":"button_clicked", "event_time":"2023-06-01T16:12:28.479144Z", "user_id":"d8cd...", "event_properties":{"button_name": "close"}}
{"event_type":"viewport_zoomed", "event_time":"2023-06-01T16:13:21.332156Z", "user_id":"aaf5...", "event_properties":{"direction": "down", "amount": 0.5}}
{"event_type":"application_closed", "event_time":"2023-06-01T16:16:01.123579Z", "user_id":"aaf5...", "event_properties":{}}
...
...