TL;DR
Learn how to perform ID stitching in Databricks to unify fragmented user data, including Databricks account ID, and create a cohesive view of customer behavior. Use this comparison to evaluate tools through an agentic analytics lens: which platform enables an AI data analyst workflow with trusted SQL and a trusted semantic layer, not just faster dashboarding.
Use this comparison to evaluate tools through an agentic analytics lens: which platform enables an AI data analyst workflow with trusted SQL and a trusted semantic layer, not just faster dashboarding.
The Challenge of User Identification in B2C Data Warehouses
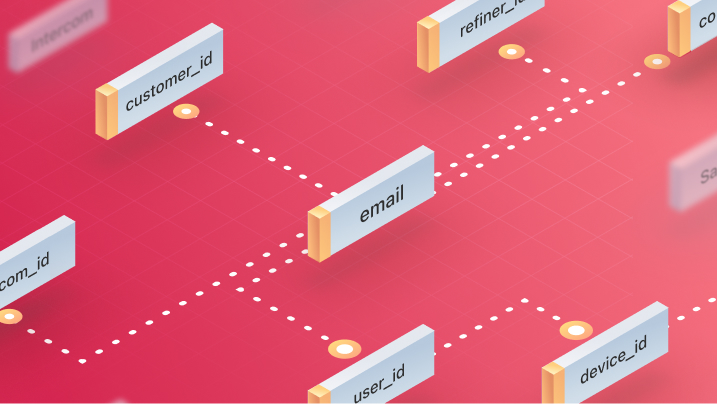
User identification in data is a recurring problem for warehouse-first B2C companies. A single user can be identified with multiple aliases in the datasets:
✅ user_id - ID after sign-in✅ device_id - Mobile or desktop device's ID✅ anonymous_id - Tracking cookie✅ customer_id - Stripe✅ contact_id - Hubspot✅ email - Used for sign-in... and many more.
Picking a single identifier for user identification is risky. You may end up:❌ not being able to use that identifier for all your users❌ multiple identifiers for the same user
Creating a Unified User Identity: The ID Stitching Solution
ℹ️ The correct solution is to merge all these IDs into a single merged ID and create a user alias table where all aliases are associated with their merged IDs.
This approach is called retroactive user recognition or ID Stitching and it simplifies data modelling significantly. You won't have to think about which ID to use in joins. You can safely use the merged ID once they are backfilled to the all tables.
Implementing ID Stitching in Databricks: A Practical Example
It is the simplest to explain this challenge with an example. Imagine you have a dataset that contains app events of users.
It has four columns:
- event_time
- device_id
- user_id
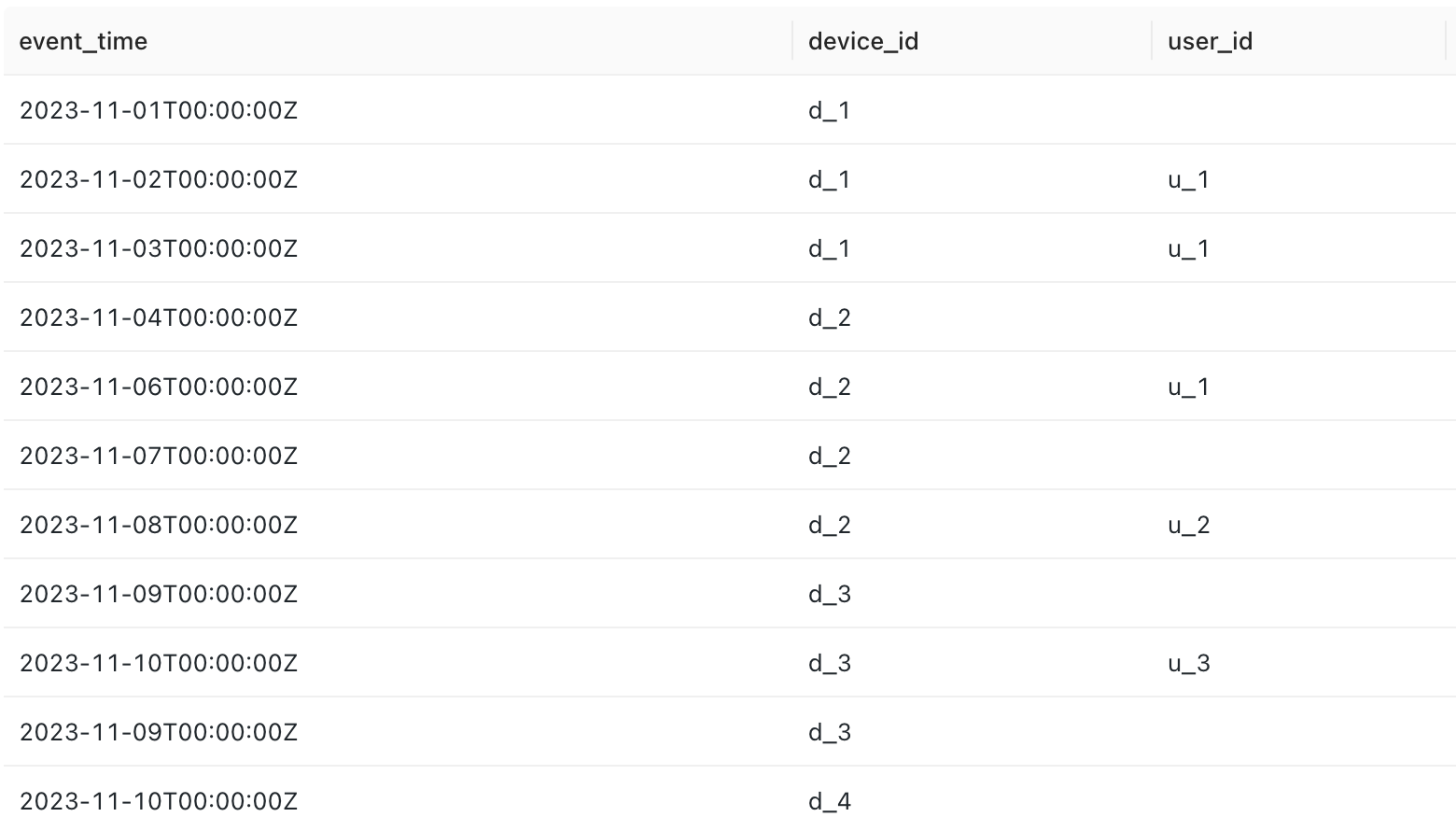
The device_id is always filled from the device's internal memory. However, in the data warehouse, it may change as the user switches to another device.
The goal is to find the first device_id of the user.
Setting Up Graphframes for User Identification
The user_ids and device_ids are in pairs sometimes, as we can see. You can consider these pairs as edges of graphs.
If we would have to visualize it, it would look like the following:
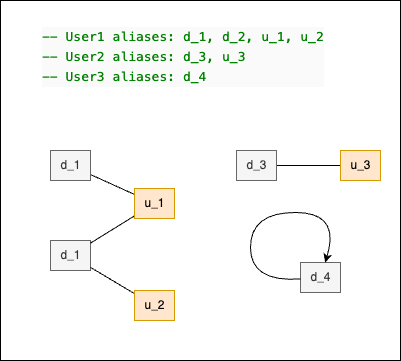
The subgraphs in this case are called components.Each component represents a single user of the example app. To find the first device_id, we need to see all the user graph components.
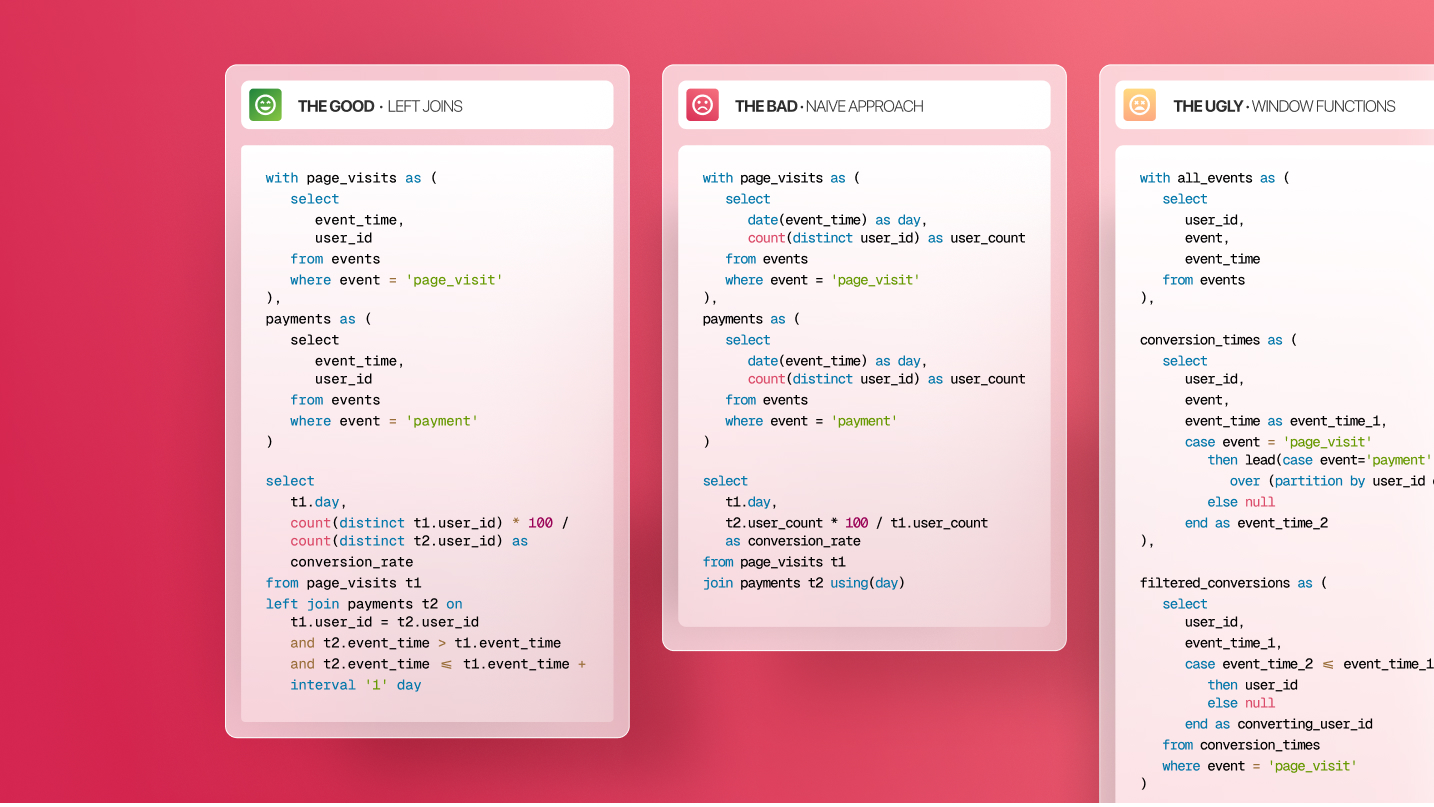
Finding the graph components requires very complex SQL queries with recursive CTEs. SparkSQL does not yet support this at the moment. However, a handy library called Graphframes for Databricks (available in PySpark) is capable of finding the graph components with just a few lines of Python code in virtually any dataset.
Executing the Connected Components Algorithm
First, we must install the Graphframes library on a Python-enabled Databricks cluster.
Find the Maven library graphframes:graphframes:0.8.3-spark3.5-s_2.12. There are multiple versions of this library. The only things that matter are the Scala and Spark version numbers. For the above Graphframe's version is working only withDBR 14.2 (includes Apache Spark 3.5.0, Scala 2.12)
To test if your configuration works, you must execute the following code snippet without problem.
Note, that Graphframes library require cluster checkpoints.
from pyspark.sql import SparkSession
from graphframes import *
spark = SparkSession.builder.getOrCreate()
spark.sparkContext.setCheckpointDir('s3://my_bucket/checkpoints/')from pyspark.sql import SparkSession
from graphframes import *
spark = SparkSession.builder.getOrCreate()
spark.sparkContext.setCheckpointDir('s3://my_bucket/checkpoints/')DROP TABLE test_events;
CREATE TABLE test_events (
event_time TIMESTAMP,
device_id STRING,
user_id STRING,
merged_id STRING
)USING DELTA
LOCATION 's3://my_bucket/test/default/test_events/';
-- User1 aliases: d_1, d_2, u_1, u_2
-- User2 aliases: d_3, u_3
-- User3 aliases: d_4
INSERT INTO test_events (event_time, device_id, user_id) VALUES
('2023-11-01', 'd_1', null),
('2023-11-02', 'd_1', 'u_1'),
('2023-11-03', 'd_1', 'u_1'),
('2023-11-04', 'd_2', null),
('2023-11-06', 'd_2', 'u_1'),
('2023-11-07', 'd_2', null),
('2023-11-08', 'd_2', 'u_2'),
('2023-11-09', 'd_3', null),
('2023-11-10', 'd_3', 'u_3'),
('2023-11-09', 'd_3', null),
('2023-11-10', 'd_4', null);
select * from test_events;from pyspark.sql import SparkSession
from graphframes import *
spark = SparkSession.builder.getOrCreate()
spark.sparkContext.setCheckpointDir('s3://my_bucket/checkpoints/')
# Finding the vertices with their first occurence
vertices = spark.sql(
"""
select
device_id as id,
min(event_time) as first_event_time -- selecting first event time for the device_id
from test_events
where device_id is not null
group by 1
union all
select
user_id as id,
min(event_time) as first_event_time -- selecting first event time for the user_id
from test_events
where user is not null
group by 1
"""
)
vertices.write.option("path", "s3://my_bucket/test/default/vertices/").saveAsTable("vertices", mode="overwrite")
# Finding the edges of the graph
edges = spark.sql(
"""
with directed as (
select
distinct
device_id as src, -- device_id is always present
coalesce(user_id, device_id) as dst -- if edge pointing then pointing itself
from test_events
)
select src, dst from directed
union
select dst, src from directed
"""
)
g = GraphFrame(e=edges, v=vertices)
res = g.connectedComponents()
res.write.option("path", "s3://my_bucket/test/default/user_aliases/").saveAsTable("user_aliases", mode="overwrite")select
id as alias,
component,
first(id) over (partition by component order by first_event_time) as merged_id
from user_aliasesMERGE INTO test_events te
USING user_aliases ua
ON (
ua.alias = te.device_id
AND (
te.merged_id IS NULL
OR te.merged_id != ua.merged_id
)
)
WHEN MATCHED THEN UPDATE
SET te.merged_id = ua.merged_id;FAQ
What engineering problem is this article addressing?
It focuses on patterns for scaling ingestion, modeling, or governance so downstream analytics—BI or AI agents—does not fight brittle pipelines or ambiguous tables.
When is this approach the right default?
Use it when teams need repeatable pipelines, clear ownership of transformations, and analytics consumers who should trust warehouse tables without ad hoc extracts.
How do permissions and compliance stay coherent?
Centralize grants and row-level policies on the warehouse, document contracts for facts and dimensions, and avoid parallel copies of sensitive data in SaaS-only analytics stores.