
TL;DR
Learn how to track experiment allocation data using arrays or nested JSON in Databricks and access it through Mitzu.io for efficient A/B test analysis. In product development, experimentation is crucial in validating hypotheses and making data-driven decisions.
Why A/B Testing Matters: 5 Key Benefits for Product Development?
In product development, experimentation is crucial in validating hypotheses and making data-driven decisions.
Running experiments, often referred to as A/B testing, allows organizations to:
- Validate Assumptions: Instead of relying on intuition or past experiences, experiments provide empirical evidence about what works best for users.
- Improve User Experience: By testing different versions of a product or feature, companies can identify the variations that enhance user satisfaction and engagement.
- Increase Conversion Rates: Experimentation helps optimize key performance indicators (KPIs) like conversion rates, leading to higher revenues and growth.
- Reduce Risk: Introducing changes to a small user segment reduces the risk of a negative impact on the entire user base.
- Foster a Culture of Innovation: Encouraging experimentation promotes a culture of learning and continuous improvement within the organization.
In this post, I will compare a few possibilities for tracking and storing experiment allocation data in event datasets in the data warehouse. I will also cover using the experimentation data in warehouse-native product analytics tools such as mitzu.io.
Mastering Experiment Data Storage: Best Practices for Event Tables
Effective storage and ingestion of experiment data are essential to derive meaningful insights.
In this post, I assume users are associated with experiment variants with an external third-party service (such as Optimizely or GrowthBook). The user variant allocation information is present on the client side (mobile app or web app), where the user-tracked events are recorded.
This means the experiment allocation data can already be attached to any event on the client side.
There are two things that we have to decide before going forward:
- Which events should have the experiment allocation data?
- How do we model experiment allocation data per event?
- How do we store the experiment data in the data warehouse?
Optimizing Event Selection: Choosing the Right Allocation Property
There are two really two options here to consider:
- Every event should have an experiment allocation property. This will simplify data analytics down the line. However, it might become problematic as experiment data takes up a lot of space and only changes sometimes.
- Creating a unique event triggered when the user is associated with experiments. This approach will keep all other events clean and will scale better. However, experiment analysis suddenly became funnel analytics, where the newly created event is the first step of the funnel.
As a rule of thumb, I suggest creating a single event to store experiment allocation data and keep all other events clean.
JSON vs Arrays: Modeling Experiment Allocation Data Effectively
The main problem with storing experiment allocation is that a single user can participate in multiple experiments at any time. Experiments have names, versions, variants, etc. In some cases, they can have other extra properties.
Here is an example of storing this information in a JSON body when tracking events.
{ "user_id": "u1", "event_time": "2024-07-17 16:00:00", "event": "experiments_allocated", "experiments": { "button_color|v1": "RED", "design_iteration|v2": "CONTROL", "experiment_22|v3": "A", } }
The main drawback of this approach is that the experiment's version is concatenated with the JSON keys. This only causes problems if you are using versioned experiments.
The other option is to store experiment allocation as an Array of JSON property:
{ "user_id": "u1", "event_time": "2024-07-17 16:00:00", "event": "experiments_allocated", "experiments": [ {"name":"button_color", "version":"v1", "variant":"RED"}, {"name":"design_iteration", "version":"v2", "variant":"CONTROL"}, {"name":"experiment_22", "version":"v3", "variant":"A"} ] }However, this approach will cause significant issues later in data analytics. I suggest sticking to the nested JSON approach. The latter is used by, for example, Optimizely. It is a great model but hard to process as a data analyst. Also, it can inherently cause data quality issues if the same experiment is twice present in the experiment_allocation event.
Databricks and Experimentation: Leveraging MAP Types for Robust Analytics
We have decided that the experimentation allocation data should be stored in only one event as nested JSONs.
Most modern data warehouses and lakes support JSON, Variant, or Map types. Any of these is sufficient for storing experiment data in the data warehouse.
Here is an example table with MAP type from Databricks.
CREATE TABLE all_events.experiments_allocated (
user_id STRING,
event_time TIMESTAMP,
event STRING,
experiments MAP<STRING, STRING>
)
This model has many benefits:
- You can list which experiments the users were experiencing. This allows you to investigate
- You can easily group by the variants of a single experiment. This will allow you to compare the variants of the experiments.
In contrast, storing data as arrays will result in more complex queries as you first need to unnest the array type.
Unleashing Insights: Post-Experiment Analysis with Warehouse-Native Tools
Storing experiment allocation data in the data has the benefit that experimentation data can be viewed in context with other critical datasets like:
- Finance datasets
- Product usage
- Marketing datasets
- Sales datasets
The fact that you can join the experiment allocation events with other product event tables based on the user_id column makes this solution the perfect candidate for warehouse-native product analytics such as Mitzu.
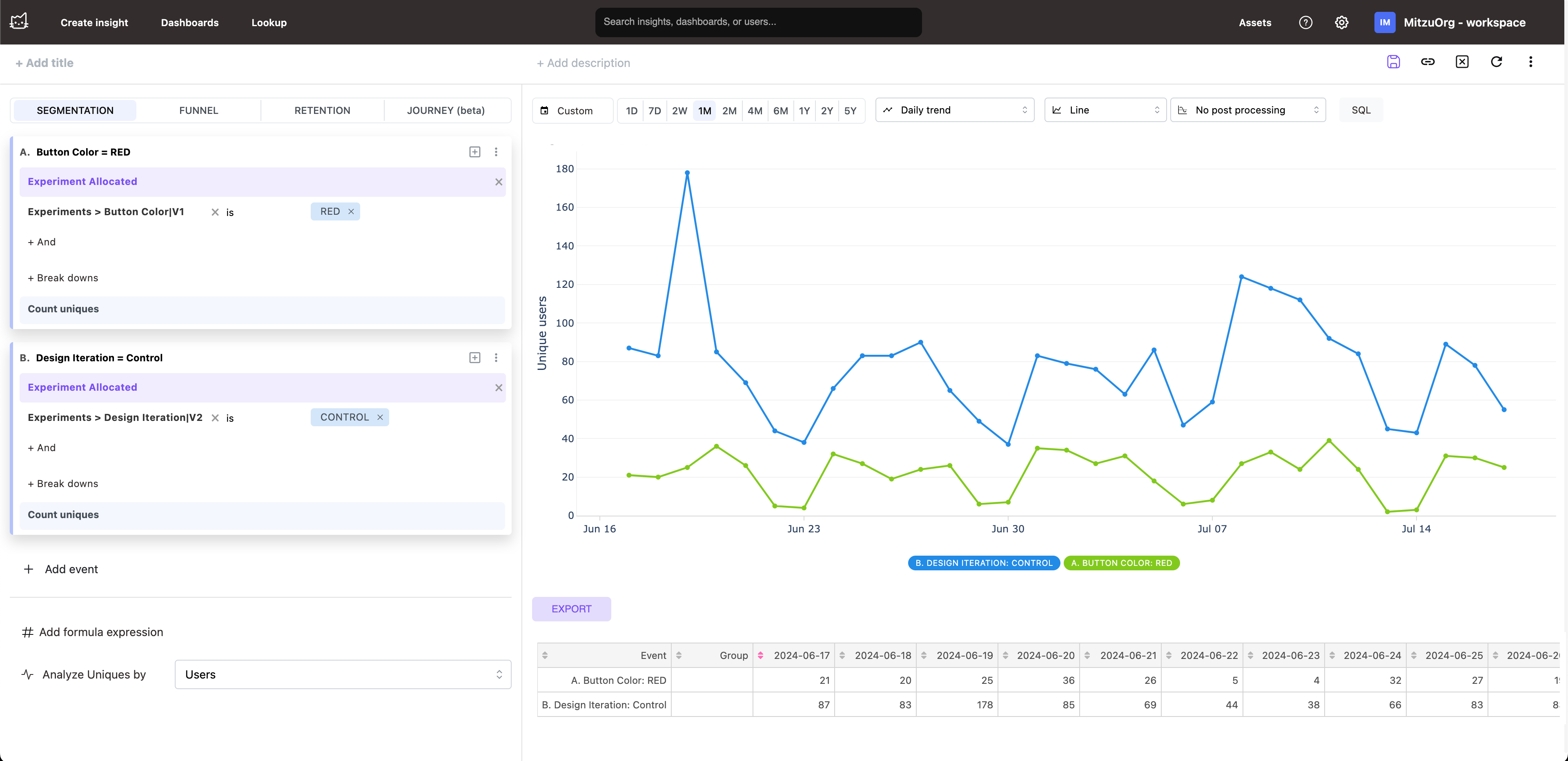
Connecting these tables takes less than a minute, and it amplifies the potential of these datasets for post-experiment analysis.
Warehouse-native product analytics enables non-technical product managers to evaluate experiments without the need for data analysts.
A/B Testing Simplified: Key Takeaways for Effective Experimentation
In this post, we covered two options for how you can track experiment allocation data on the client side:
- Arrays of JSONs property
- Nested JSON property
We then showed how to store the experiment_allocation table in Databricks where the experiments property corresponds to a column with MAP
Last but not least, we showed how to access this data from Mitzu, a warehouse-native product analytics solution.
{
"user_id": "u1",
"event_time": "2024-07-17 16:00:00",
"event": "experiments_allocated",
"experiments": {
"button_color|v1": "RED",
"design_iteration|v2": "CONTROL",
"experiment_22|v3": "A",
}
}{
"user_id": "u1",
"event_time": "2024-07-17 16:00:00",
"event": "experiments_allocated",
"experiments": [
{"name":"button_color", "version":"v1", "variant":"RED"},
{"name":"design_iteration", "version":"v2", "variant":"CONTROL"},
{"name":"experiment_22", "version":"v3", "variant":"A"}
]
}

